Modelling DOM elements with Python class¶
One of the core feature of manen is to provide some classes that will allow to modelize most of the elements in a HTML page. This design pattern, known as Page Object Model, will allow you to have an easy interface between your application and the web interface. To quote Martin Fowler:
A page object wraps an HTML page, or fragment, with an application-specific API, allowing you to manipulate page elements without digging around in the HTML.
A page object should also provide an interface that’s easy to program to and hides the underlying widgetry in the window page.
The page object should encapsulate the mechanics required to find and manipulate the data in the page itself. A good rule of thumb is to imagine changing the concrete page -in which case the page object interface shouldn’t change.
With manen, the page that you want to modelize will be represented by a class that inherits from manen.page_object_model.Page. All the elements inside this page will be represented by manen.page_object_model.Elements and its derivates.
Let’s explore together how to apply the page object model design pattern by exploring the online PyPI page of manen.
Basic DOM interacting¶
First things first, we need a WebDriver to be able to browse the Internet. Note that we will use here a manen browser but it will work the same with a Selenium WebDriver. Once initialized, we will go PyPI home page.
[1]:
from IPython.display import Image
from tempfile import NamedTemporaryFile
from manen.browser import ChromeBrowser
[2]:
browser = ChromeBrowser.initialize(proxy=None, headless=False, window_size=(1152, 864))
browser.get("https://pypi.org")
[3]:
browser.highlight("input[id='search']")
with NamedTemporaryFile(suffix='.png') as f:
browser.save_screenshot(f.name)
screenshot = Image(f.name)
screenshot
[3]:
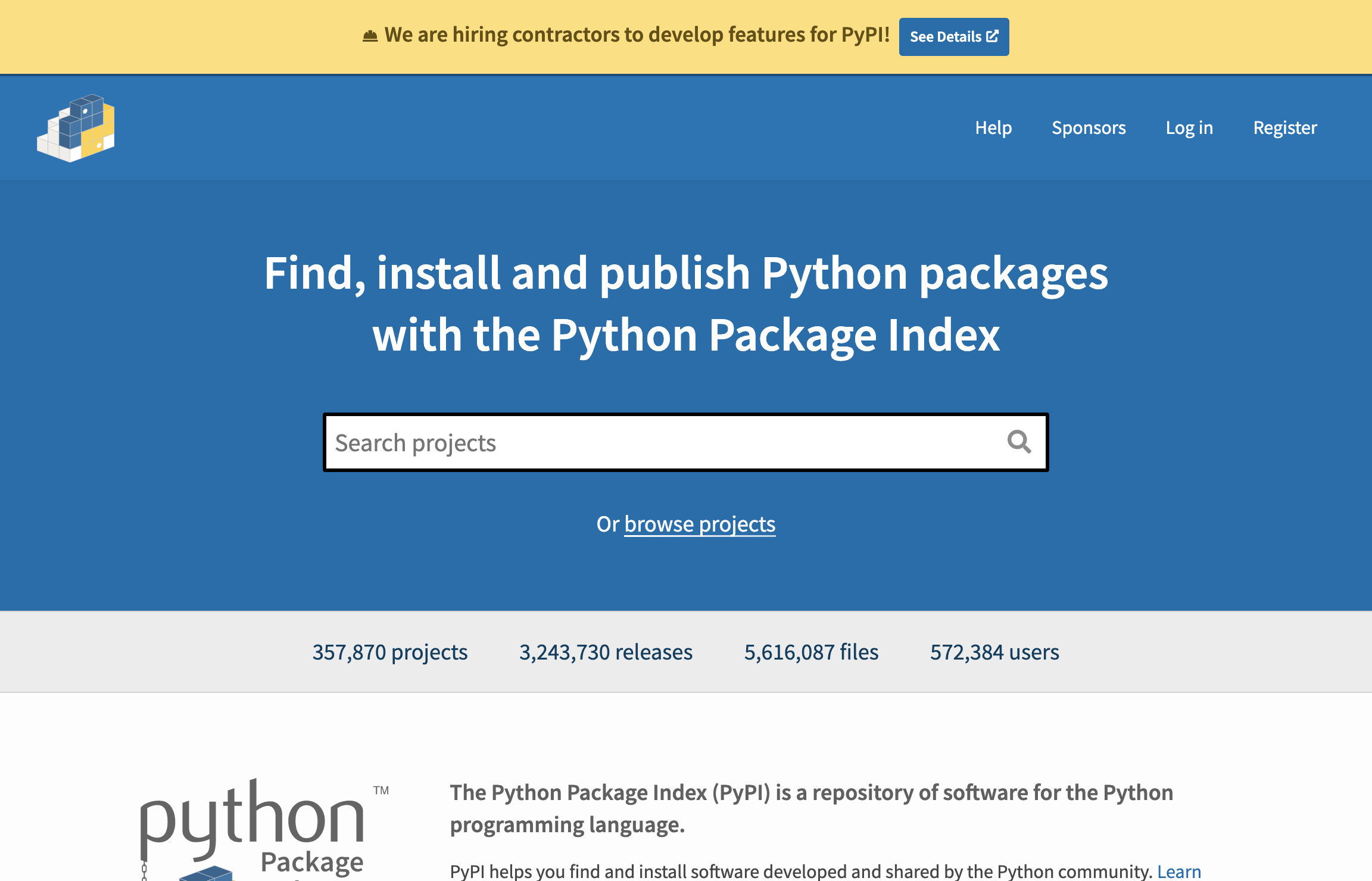
What we want to do here is to be able to interact with the input search bar to fill it with the query manen. To do so, we will start by creating a PyPIHomePage class, inheriting from HomePage; all the attributes of this class will represent one element of the UI.
In order to represent the search bar as a manen element, we will use InputElement, that will allow us to easily fill a value inside. To initialize an element, you need to provide the selectors that will be used to identify the element inside the HTML source code. Note that instead of only one selector, you can specify a list of selectors: in this case, manen will try each selector until one returns a result.
Once the page is modelized, we have to create an instance by initializing it with the Browser or WebDriver used to navigate online.
[4]:
from typing import Annotated
from manen.page_object_model.webarea import Page
from manen.page_object_model import dom
class PyPIHomePage(Page):
query = Annotated[dom.Input, dom.CSS("input[id='search']")]
page = PyPIHomePage(browser)
We can now interact directly with the search by simply setting a value to page.query; this is the goal of manen: having very Pythonic way to retrieve and interact with a HTML page.
[5]:
from selenium.webdriver.common.keys import Keys
page.query = "manen selenium"
page.query += Keys.ENTER
We are now on the results page matching our query; let’s modelize this page once again.
[6]:
browser.highlight("ul[aria-label='Search results'] li")
with NamedTemporaryFile(suffix='.png') as f:
browser.save_screenshot(f.name)
screenshot = Image(f.name)
screenshot
[6]:
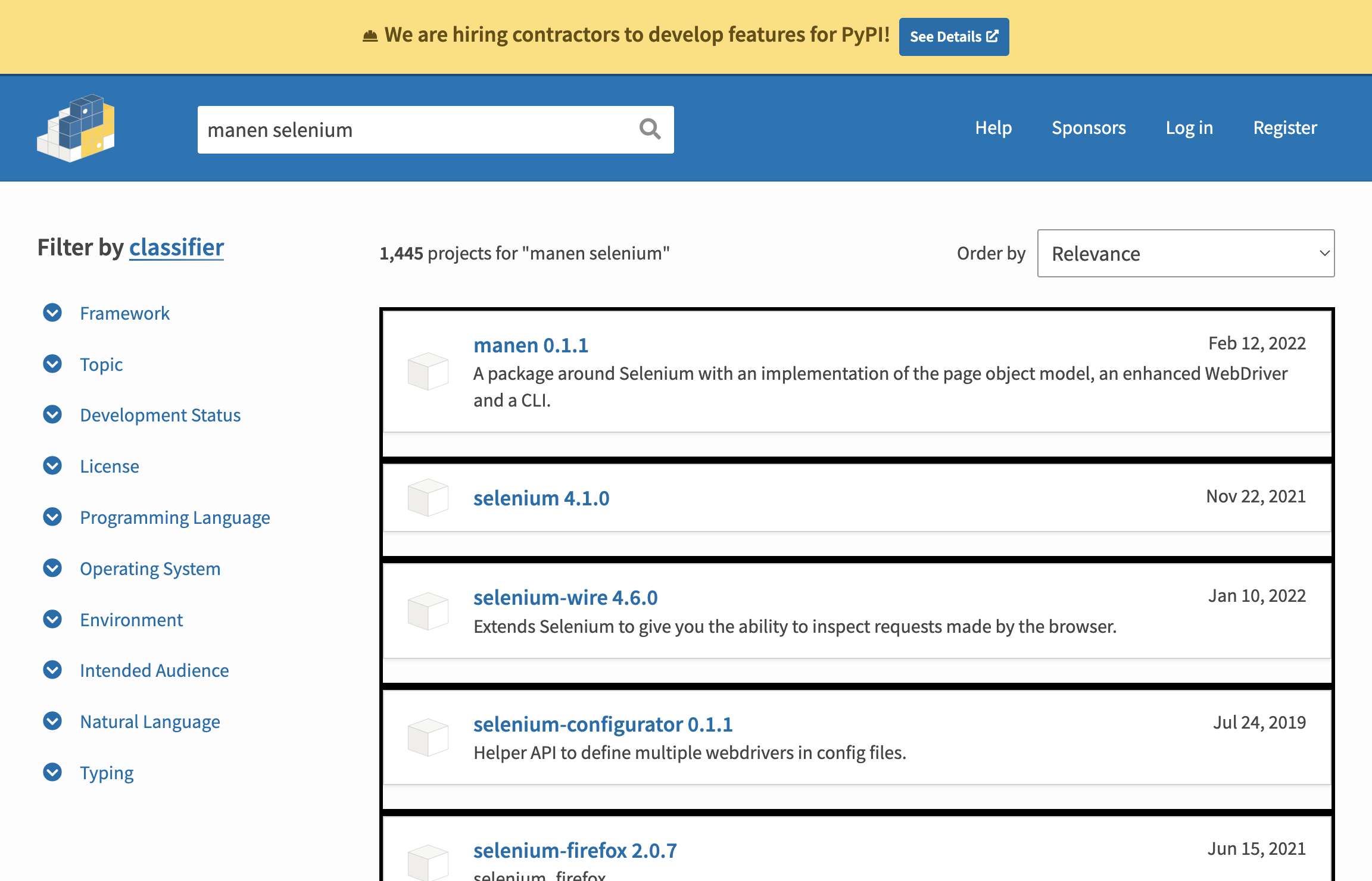
This page can contain unique elements (like the number of results matching our query), but also some elements that can be repeated; this is for example the case for the result frames. Each frame has the same structure: in manen, this is called a region, represented with a Region. A region will itself contain several elements.
Inside each frame, we want to retrieve the information about a package like the name, URL, release date… Each of this piece of information can have its own type in Python (a string, a datetime, an integer…). manen provides several kind of elements that will extract the information for you; at the end, you will obtain directly what you need, preventing you to use methods of a Selenium WebElement to extract the real data you want.
Besides the selector(s), an Element can also be initialized with the following keyword arguments:
wait: maximum number of seconds to wait until the element arrived in the HTML pagedefault: default value to be returned if the element matches nothing in the HTML page
At the end, this search results page can be modelized as follow:
[7]:
from datetime import datetime
from manen.page_object_model.webarea import WebArea
class SearchResultPage(Page):
class Result(WebArea):
name: Annotated[str, dom.CSS("h3 span.package-snippet__name")]
version: Annotated[str, dom.CSS("h3 span.package-snippet__version")]
link: Annotated[dom.HRef, dom.CSS("a.package-snippet")]
description: Annotated[str, dom.CSS("p.package-snippet__description")]
release_date: Annotated[datetime, dom.CSS("span.package-snippet__released")]
nb_results: Annotated[
int,
dom.XPath("//*[@id='content']//form/div[1]/div[1]/p/strong"),
]
results: Annotated[
list[Result],
dom.CSS("ul[aria-label='Résultats de recherche'] li"),
]
page = SearchResultPage(browser)
print("Number of results:", page.nb_results)
Number of results: 1445
page.results will be a list of special classes, that will contain all the elements we have specified inside the region.
[8]:
result = page.results[0]
result
[8]:
<__main__.SearchResultPage.ResultRegions at 0x107fb0a30>
[9]:
print('Name:', result.name)
print('Version:', result.version)
print('Release date:', result.release_date)
print('URL:', result.link)
Name: manen
Version: 0.1.1
Release date: 2022-02-12 00:00:00
URL: https://pypi.org/project/manen/
/Users/kodjo/.local/share/virtualenvs/manen-6kXEiGtM/lib/python3.8/site-packages/dateparser/date_parser.py:35: PytzUsageWarning: The localize method is no longer necessary, as this time zone supports the fold attribute (PEP 495). For more details on migrating to a PEP 495-compliant implementation, see https://pytz-deprecation-shim.readthedocs.io/en/latest/migration.html
date_obj = stz.localize(date_obj)
[10]:
browser.quit()